今天在网上闲逛的时候发现了读了一位“大神”的面试经历,想想自己工作一年了,还是在小打小闹,索性趁着现在工作不忙,来补习下功课。
从 HashMap 开始吧!
首先,这个东西比较常见,大家都在用却鲜有人思考,该怎么实现一个具有相同功能的 Map ,让他按照键值对来存储数据,能够随机存取,并且可以方便的遍历、查询、删除。其次,这块东西比较简单。线程不同步就不涉及到 synchronized , Thread 等;结构上够简单,线性表存储,又不用考虑内存分配回收。
闲话不多说了,开始解剖这只 Map ,披着 Hash 的皮的 Map 。
结构
HashMap 内部是一个数组,和 HashList 感觉差不多,都是长度可以动态增长的数组。差别在 Map 和 List 是用不同存储单元和存储形式来存放数据。 HashMap 的数组存储单元是 Entry 类。下面来看 HashMap 源码的属性,上代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
| static final int DEFAULT_INITIAL_CAPACITY = 16; static final int MAXIMUM_CAPACITY = 1 << 30; 默认加载因子,加载因子是一个比例。 当HashMap的数据大小>=容量*加载因子时, HashMap会将容量扩容。 默认 0.75 平衡了存储空间的占用和数组元素遍历的时间。 */ static final float DEFAULT_LOAD_FACTOR = 0.75f; transient Entry[] table; transient int size; int threshold; final float loadFactor; transient volatile int modCount;
|
对于上面的代码有几点需要记录一下:
transient :Java 的 serialization 提供了一种持久化对象实例的机制。当持久化对象时,可能有一个特殊的对象数据成员,我们不想
用 serialization 机制来保存它。为了在一个特定对象的一个域上关闭 serialization ,可以在这个域前加上关键字 transient 。
Volatile:Volatile修饰的成员变量在每次被线程访问时,都强迫从主内存中重读该成员变量的值。
上面那一坨,估计最令人好奇的就是 Entry 类的实现啦。它是 HashMap 的一个内部类,以键值对的形式来存储放进 map 的值,它本身结构和方法都很简单,上代码:
1 2 3 4 5 6 7
| static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; final int hash; }
|
这就是 HashMap 内部结构的代码。
HashMap 的初始化、存取、增加元素、删除元素的过程
下面将通过一个代码的运行过程来解释 HashMap 的各种方法的实现。
首先给出的是,我们将要运行的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
| import java.util.HashMap; import java.util.Map; /** * @author wenming.fu * @date 15/10/2013 */ public class TestHashMap { public static void main(String[] args) { Map<String, String> map = new HashMap<String, String> (); truetrue truetrue truetruefor (int i = 0; i < 18; i++) { truetruetruemap.put("key" + i, "value" + i); truetrue} truetruemap.put(null, "NUL"); truetruemap.put("18", "value18"); truetrue truetrue truetrueString value10 = map.get("key10"); truetrueSystem.out.println(value10); truetrue truetrueif (map.containsKey("18")) truetruetruemap.remove("18"); truetrue truetruemap.clear(); true} }
|
1. 构造方法
当我们 new 一个 HashMap 的时候,和其他对象一样,JVM 会调用这个构造方法来实例化一个对象。HashMap 提供了四种构造方法:
1 2 3 4
| public HashMap() public HashMap(int initialCapacity) public HashMap(int initialCapacity, float loadFactor) public HashMap(Map<? extends K, ? extends V> m)
|
前面三种大同小异,基本步骤都是确定 loadFactor、threshold 等基本属性,然后table = new Entry[capacity];创建一个空的 Entry 数组作为当前的 table。
第四种有 putAllForCreate(Map m) 的过程,稍后再说 put 。
那么上面的代码实例化一个 HashMap 的运行过程是怎样的呢?调用默认无参的构造方法,初始化一个长度为 16 的数组。
2. 存放数据
存放数据会调用put方法,用来在数组里增加一个键值对。看代码吧:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67
| public V put(K key, V value) { if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; } void addEntry(int hash, K key, V value, int bucketIndex) { true Entry<K,V> e = table[bucketIndex]; true true /** true Entry(int h, K k, V v, Entry<K,V> n) { value = v; //将现存的键值对放到链表的后面 next = n; key = k; hash = h; } */ table[bucketIndex] = new Entry<K,V>(hash, key, value, e); if (size++ >= threshold) resize(2 * table.length); } void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; transfer(newTable); table = newTable; threshold = (int)(newCapacity * loadFactor); }
|
至此存放数据的全部步骤已经看完了,用一张图来表示我们的例子代码的运行过程(数据不一定存放在图中的位置,但是 resize 等操作已在途中标示):
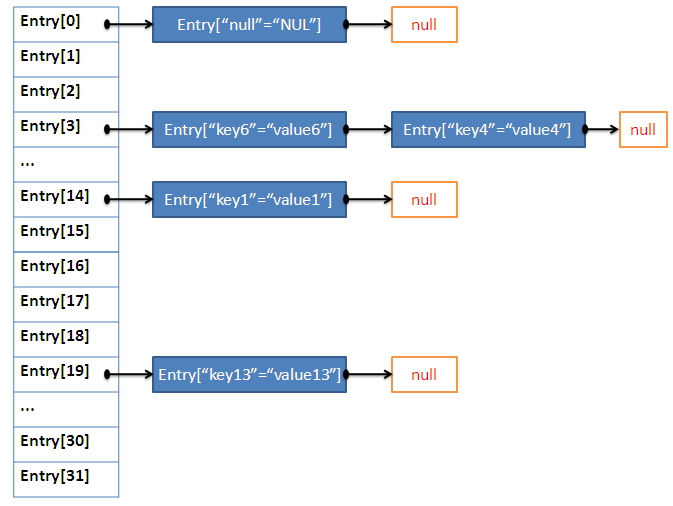
3. 取出数据
搞明白了怎么存放数据的之后,从线性表中取出数据的过程就比较简单啦,上代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
| public V get(Object key) { if (key == null) return getForNullKey(); int hash = hash(key.hashCode()); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } return null; }
|
这就是取值的过程,毫无波折。不再赘述。
4. 删除数据
HashMap 还提供了一个 Remove(Object key) 的方法,下面看看怎么实现的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
| public V remove(Object key) { Entry<K,V> e = removeEntryForKey(key); return (e == null ? null : e.value); } final Entry<K,V> removeEntryForKey(Object key) { int hash = (key == null) ? 0 : hash(key.hashCode()); int i = indexFor(hash, table.length); Entry<K,V> prev = table[i]; Entry<K,V> e = prev; while (e != null) { Entry<K,V> next = e.next; Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { modCount++; size--; if (prev == e) table[i] = next; else prev.next = next; e.recordRemoval(this); return e; } prev = e; e = next; } return e; }
|
上面的删除操作也不是特别复杂,主要就是单链表的删除操作。
还有一个方法是 clear() ,是清空整个 Map ,我们来看看怎么实现的:
1 2 3 4 5 6 7 8 9 10
| public void clear() { modCount++; Entry[] tab = table; for (int i = 0; i < tab.length; i++) tab[i] = null; size = 0; }
|
结语
OK,上面就是 HashMap 的实现原理了,可以看出以下几点:
- HashMap 是用线性的数组来存放数据的,只是存放的位置经过一些列的计算这样它就能快速的查找、遍历了;同时,它在数组元素中维护了一个单向链表,用来确保 index 相同 key 不同的情况能正确处理,还保证了 key 相同的情况的正确取值。
- HashMap 放进同样的 key 的话,会把以前的值放在数组中链表的后面,用 get 取值的时候就取不到了,但是并不会报错。
- HashMap 的 loadFactor 设定关系到 resize 的次数,而 resize 会耗费很多的资源,因此根据自己的数据和需求合理设定初始化容量和 loadFactor 很有必要。
- HashMap 的存取是线程不同步的操作,要小心使用。如果需要线程同步,使用下面的方式。
Map map = Collections.synchronizedMap(new HashMap());
- HashMap 数据的存放位置不确定,因此最好不要根据位置来取数据。如果需要按照 put 的顺序来访问元素,可以使用其子类
LinkedHashMap 。
基本上就这些啦。
OVER!
